How High-Accuracy Data Labeling Improved
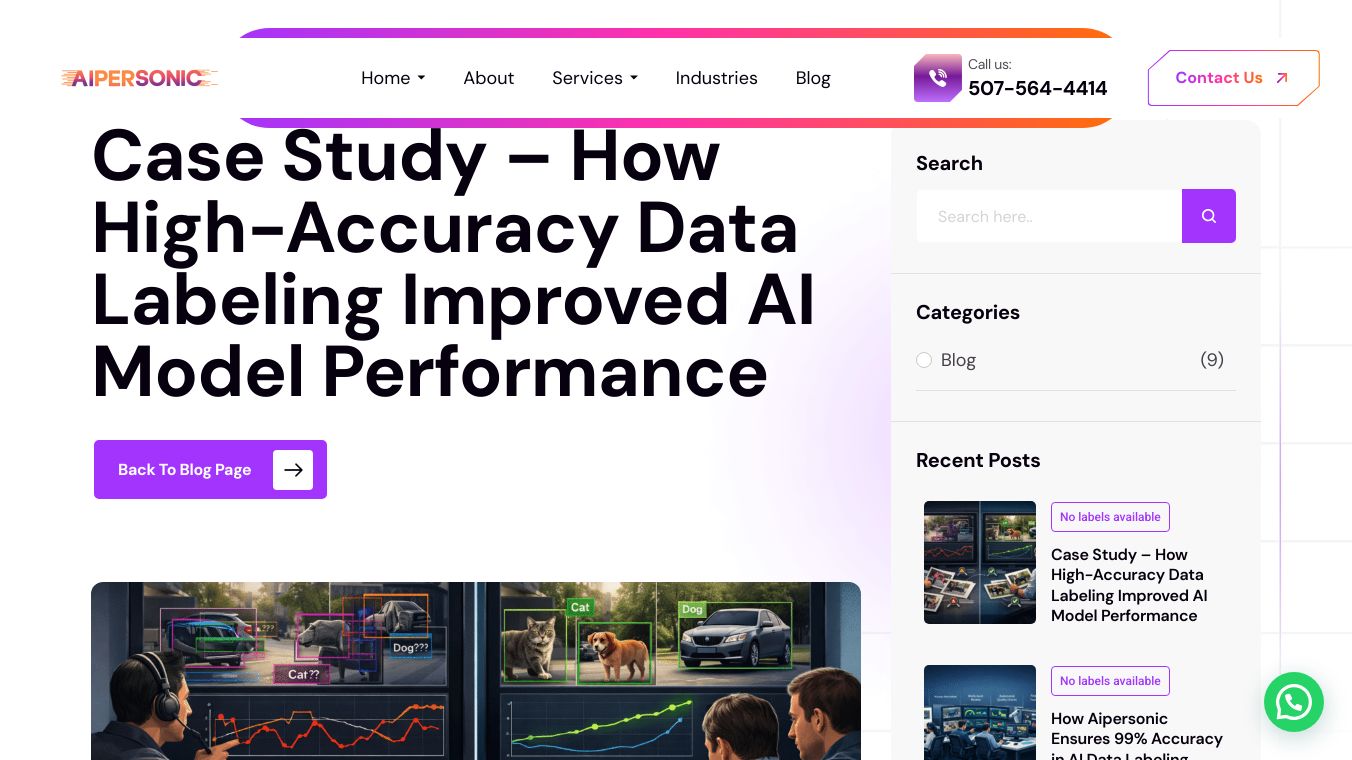
What is How High-Accuracy Data Labeling Improved?
How High-Accuracy Data Labeling Improved is a process that ensures the data used to train AI models is precise and of high quality. This involves annotating data with relevant labels, which helps AI systems understand and interpret the data accurately. The quality of data labeling directly impacts the performance and reliability of AI models. Poorly labeled data can lead to biased or incorrect outcomes, making high-accuracy data labeling essential for effective AI applications.
Benefits
High-accuracy data labeling offers several key advantages:
- Improved AI Performance: Accurate data labeling ensures that AI models perform better and provide reliable results.
- Reduced Bias: High-quality labeled data helps minimize biases in AI systems, leading to fairer and more accurate outcomes.
- Enhanced Reliability: Reliable data labeling processes ensure that AI models are trained on data that is both precise and trustworthy.
- Efficiency: Advanced technologies like machine learning and automation streamline the data labeling process, making it more efficient and cost-effective.
Use Cases
High-accuracy data labeling is crucial in various industries and applications, including:
- Healthcare: Accurate data labeling helps in diagnosing diseases, predicting patient outcomes, and personalizing treatment plans.
- Autonomous Vehicles: Reliable data labeling ensures that self-driving cars can accurately interpret and respond to their environment.
- Finance: High-quality data labeling improves fraud detection, risk assessment, and customer service in the financial sector.
- E-commerce: Accurate data labeling enhances product recommendations, customer segmentation, and inventory management.
Additional Information
The process of high-accuracy data labeling involves several steps, including data collection, annotation, and validation. Each step is crucial in ensuring that the final labeled data is accurate and reliable. Data collection involves gathering relevant data from various sources, while annotation involves adding labels to the data. Validation is the final step, where the labeled data is reviewed to ensure its accuracy. This comprehensive approach to data labeling helps to minimize errors and ensure that the data used to train AI models is of the highest quality.
In conclusion, high-accuracy data labeling is a fundamental aspect of AI development, playing a pivotal role in the creation of accurate and reliable AI models. By investing in this process and leveraging advanced technologies, organizations can ensure that their AI systems are trained on high-quality data, leading to better outcomes and more effective AI applications.
This content is either user submitted or generated using AI technology (including, but not limited to, Google Gemini API, Llama, Grok, and Mistral), based on automated research and analysis of public data sources from search engines like DuckDuckGo, Google Search, and SearXNG, and directly from the tool's own website and with minimal to no human editing/review. THEJO AI is not affiliated with or endorsed by the AI tools or services mentioned. This is provided for informational and reference purposes only, is not an endorsement or official advice, and may contain inaccuracies or biases. Please verify details with original sources.

Comments
Please log in to post a comment.