DINO V3
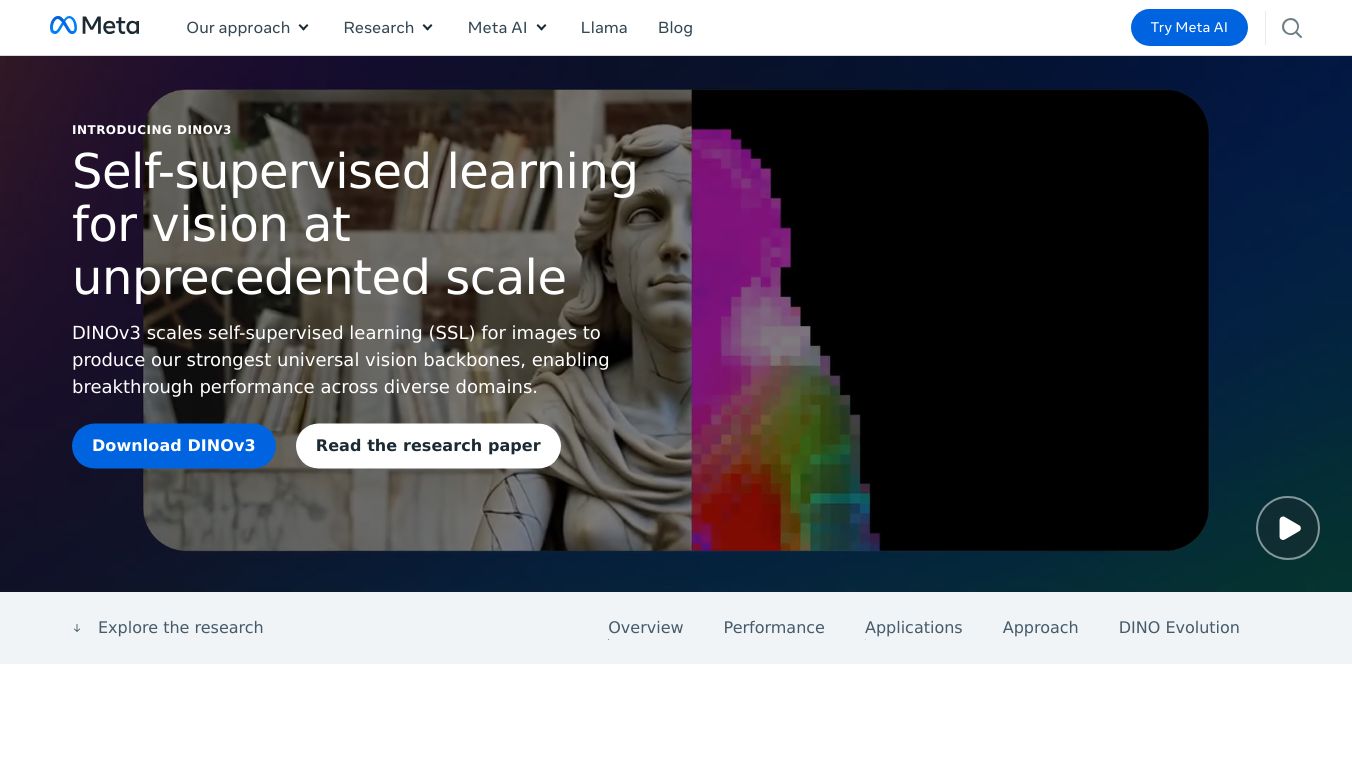
DINOv3 is a powerful self-supervised learning model designed to create advanced image representations without needing human annotations. It scales self-supervised learning to unprecedented levels, using 7 billion parameters and 1.7 billion images, making it highly efficient and capable of delivering state-of-the-art performance across various visual tasks. DINOv3 stands out for its ability to perform exceptionally well in diverse domains, from object detection in web imagery to canopy height mapping in satellite and aerial imagery. Its versatile backbone provides high-resolution dense features that enable leading performance in tasks like object detection, depth estimation, and segmentation, all without requiring any fine-tuning. The model suite includes a range of sizes and architectures, catering to different use cases, including efficient ConvNeXt models for on-device deployment. DINOv3 sets a new standard in vision foundation models, outperforming weakly-supervised models in various tasks such as fine-grained image classification, semantic segmentation, and object tracking in video. This model is particularly useful in scenarios where annotations are scarce or costly, making it a valuable tool for researchers and developers. DINOv3 has been successfully applied in various real-world applications, such as measuring tree canopy heights for reforestation monitoring by the World Resources Institute, enabling vision tasks for Mars exploration robots by NASA JPL, and pre-training on organoid images for cancer treatment response prediction by Orakl Oncology. The model's self-supervised pre-training allows it to learn general-purpose visual representations from large unlabeled datasets, which can then be easily tailored for specific tasks with a lightweight adapter trained on a small amount of annotated data. DINOv3 represents a significant milestone in the evolution of self-supervised learning, building upon the progress of DINOv2 with larger model sizes and more extensive training data, particularly focusing on dense features.
This content is either user submitted or generated using AI technology (including, but not limited to, Google Gemini API, Llama, Grok, and Mistral), based on automated research and analysis of public data sources from search engines like DuckDuckGo, Google Search, and SearXNG, and directly from the tool's own website and with minimal to no human editing/review. THEJO AI is not affiliated with or endorsed by the AI tools or services mentioned. This is provided for informational and reference purposes only, is not an endorsement or official advice, and may contain inaccuracies or biases. Please verify details with original sources.

Comments
Please log in to post a comment.