TurboQuant-MoE:8.5x KV-Cache Compression
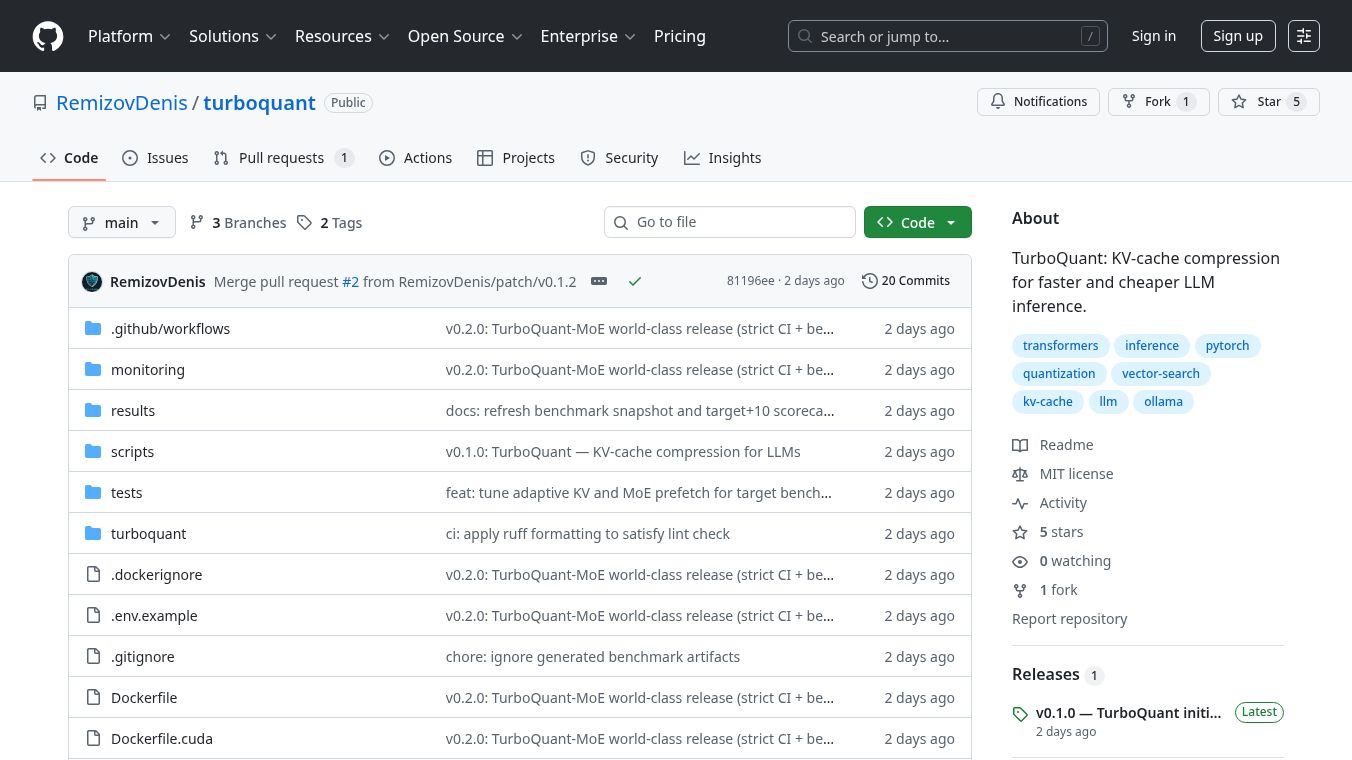
TurboQuant-MoE is a tool designed to help large language models run more efficiently, especially when dealing with long pieces of text or complex models. It works by compressing the memory used to store information, known as the KV cache, and by managing how different parts of the model, called experts, are accessed.
Benefits
TurboQuant-MoE significantly reduces the amount of memory needed for the KV cache, compressing it by an average of 8.53 times. This means models can handle longer texts without running out of memory. It also ensures that important information is not lost, as shown by 100% recall in tests. The tool efficiently manages the model's experts, keeping the most needed ones ready and saving about 6.42 GB of GPU memory. This leads to much faster processing, with a projected decode speed increase of up to 8.48 times in certain situations.
Use Cases
This tool is useful for anyone running large language models that require a lot of memory, particularly for tasks involving long contexts or models with many experts (Mixture-of-Experts or MoE models). It can be integrated with popular platforms like HuggingFace Transformers, vLLM for production environments, and Ollama. This makes it suitable for developers and researchers working on AI applications that need to be fast and memory efficient.
Vibes
Performance benchmarks show that TurboQuant-MoE achieves a high compression ratio of 8.54x for the KV cache compared to standard methods. The expert cache system boasts a 96.8% hit rate and 96.8% prefetch readiness, indicating that the system is very good at predicting and preparing the necessary components. The average time to load data is low at 0.69 ms, and it saves a substantial 6.424 GB of GPU memory.
Additional Information
TurboQuant-MoE supports a variety of popular models, including Mixtral, DeepSeek, Qwen, OLMoE, Arctic, and Llama-3. The project is open source, licensed under MIT, and welcomes contributions from the community. It is built upon the original TurboQuant algorithm and software, with enhancements for dynamic expert caching and other advanced features.
This content is either user submitted or generated using AI technology (including, but not limited to, Google Gemini API, Llama, Grok, and Mistral), based on automated research and analysis of public data sources from search engines like DuckDuckGo, Google Search, and SearXNG, and directly from the tool's own website and with minimal to no human editing/review. THEJO AI is not affiliated with or endorsed by the AI tools or services mentioned. This is provided for informational and reference purposes only, is not an endorsement or official advice, and may contain inaccuracies or biases. Please verify details with original sources.
Other Interesting AI Tools

Comments
Please log in to post a comment.