SenseNova U1
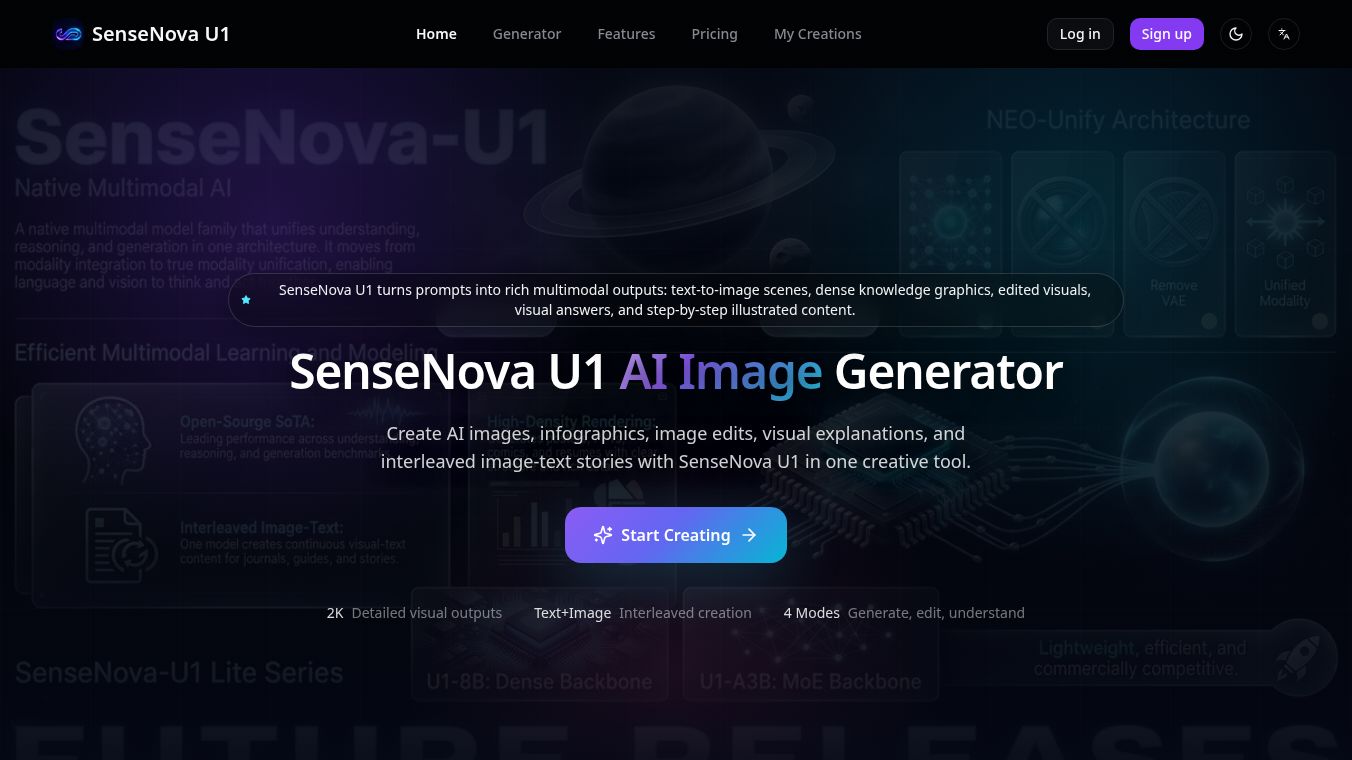
SenseNova U1 is a new type of artificial intelligence model that combines understanding and creating both text and images in one system. Instead of using separate parts to handle different types of data, this model treats language and pictures as a single unified stream. It was released in April 2026 and is designed to be open source, meaning developers can use it for free to build their own applications. The technology is built on a unique architecture called NEO-Unify which removes traditional barriers between visual and text processing. This allows the system to think and act across different media types without needing extra translation steps. The model is currently available in two sizes, one with 8 billion parameters and another with 3 billion parameters, both of which are highly efficient for running on standard hardware.
Benefits
The main advantage of SenseNova U1 is its ability to handle complex tasks that require both visual and textual reasoning. Because it unifies modalities, it can generate coherent stories that mix text and images in a single flow. This is useful for creating practical guides or travel diaries where images and words must work together seamlessly. The model also excels at rendering high-density information, making it perfect for creating posters, presentations, comics, and resumes. It sets a new standard for open-source models by achieving top performance on benchmarks for understanding, reasoning, and generation. Users benefit from excellent cost efficiency because the models are compact yet powerful. Additionally, the system supports advanced features like vision-language-action tasks and world modeling, which allow it to understand and predict actions in the real world.
Use Cases
Developers and businesses can use SenseNova U1 for a wide variety of creative and analytical projects. One common use case is creating educational materials. The model can generate structured layouts for knowledge illustrations and infographics that explain complex concepts clearly. Another application is building interactive agents for customer service or education. These agents can answer questions about visual content, such as reading a menu or analyzing a scientific diagram. The model is also ideal for content creation tools that need to produce travel diaries or illustrated tutorials. For example, it can generate a step-by-step cooking guide that includes images for each stage of the process. Image editing is another strong use case where the model can perform logical edits, such as changing the color of an object or predicting how an object will change over time. Finally, the system can be deployed in production environments using specialized software stacks that offer fast inference speeds for large images.
Pricing
SenseNova U1 is released under the Apache 2.0 License, which means it is free to use for commercial and non-commercial projects. There are no licensing fees or subscription costs associated with the model itself. The project is open source, allowing anyone to download and run the models on their own computers or servers. While the model is free, users may need to invest in their own hardware to run the inference, especially for high-resolution image generation. The project team has not announced any paid services or inference providers for this specific model, keeping the ecosystem focused on community-driven development and self-hosted solutions.
Vibes
The community response to SenseNova U1 has been very positive, with significant interest in the technology. The model has already seen over 1,300 downloads in the first month of its release, indicating strong demand from developers and researchers. The project has established a WeChat group where users can share feedback, get support, and stay updated on new developments. The model is recognized for setting a new standard for open-source multimodal systems, with many users praising its efficiency and performance compared to commercial alternatives. The release of the Lite series in two sizes has been well-received because it offers a balance between performance and resource usage. The project documentation and code examples are clear, making it accessible for both technical and non-technical users to get started quickly.
Additional Information
SenseNova U1 was officially released on April 27, 2026. The project is led by SenseNova and is built on a proprietary architecture that eliminates the need for separate visual encoders and auto-encoders. The models are trained using a multi-stage process that includes understanding warmup, generation pre-training, and unified fine-tuning. For production deployment, the team has co-designed a dedicated inference stack based on LightLLM and LightX2V which offers significant speed improvements. The model supports a context length of up to 32,000 tokens, which is useful for handling long documents or complex scenes. While the model is highly capable, it does have some limitations, such as challenges with fine-grained details of human bodies and occasional text rendering errors. The project plans to release larger-scale versions in the future to further enhance performance. The community is encouraged to join the WeChat group to contribute to the ongoing development and improvement of the technology.
This content is either user submitted or generated using AI technology (including, but not limited to, Google Gemini API, Llama, Grok, and Mistral), based on automated research and analysis of public data sources from search engines like DuckDuckGo, Google Search, and SearXNG, and directly from the tool's own website and with minimal to no human editing/review. THEJO AI is not affiliated with or endorsed by the AI tools or services mentioned. This is provided for informational and reference purposes only, is not an endorsement or official advice, and may contain inaccuracies or biases. Please verify details with original sources.
Comments
Please log in to post a comment.