gpt-realtime-1.5 by OpenAI
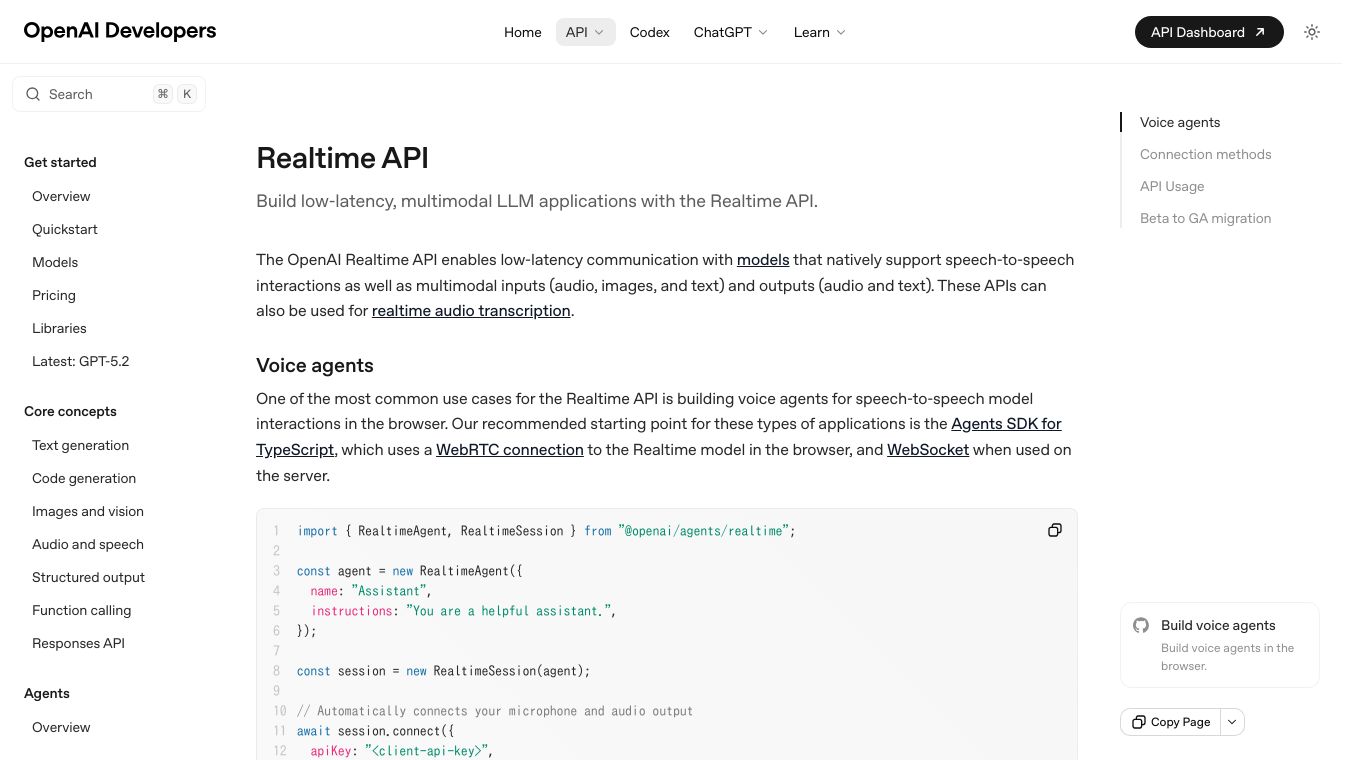
GPT-Reatime-1.5 by OpenAI is a top-tier audio model built for voice agents and customer service applications. It excels at handling audio input and output, offering impressive speed and a large 32,000 token context window. This means it can process and remember a significant amount of information for more complex conversations. The model can understand text, audio, and images, and can respond using text and audio. Its knowledge base is current up to September 30, 2024.
Benefits
GPT-Reatime-1.5 provides high performance for audio tasks, ensuring quick and efficient interactions. Its extensive context window allows for deeper understanding and more coherent responses in conversations. The model's ability to process multiple input types like text, audio, and images makes it versatile for various applications.
Use Cases
This model is ideal for creating advanced voice agents that can handle customer support inquiries. It can be used in applications that require real-time audio processing, such as interactive voice response systems or live translation services. Businesses can leverage GPT-Reatime-1.5 to enhance customer interactions through more natural and responsive voice-based communication.
Pricing
Pricing for GPT-Reatime-1.5 is based on token usage. Text input costs $4.00 per million tokens, and text output costs $16.00 per million tokens. Audio input is priced at $32.00 per million tokens, with audio output at $64.00 per million tokens. Image input is $5.00 per million tokens. There are also fees for tool-specific models.
Vibes
While specific public reviews are not detailed in the provided information, the model is described as OpenAI's flagship audio model, suggesting a high level of capability and performance expected by its developers for voice agent and customer support applications.
Additional Information
GPT-Reatime-1.5 supports various API endpoints, including chat completions, real-time interactions, and audio processing. Users can utilize snapshots to lock in specific model versions for consistent results. Rate limits are applied to ensure API stability, with different tiers offering varying levels of requests and token limits per minute and day.
This content is either user submitted or generated using AI technology (including, but not limited to, Google Gemini API, Llama, Grok, and Mistral), based on automated research and analysis of public data sources from search engines like DuckDuckGo, Google Search, and SearXNG, and directly from the tool's own website and with minimal to no human editing/review. THEJO AI is not affiliated with or endorsed by the AI tools or services mentioned. This is provided for informational and reference purposes only, is not an endorsement or official advice, and may contain inaccuracies or biases. Please verify details with original sources.
Comments
Please log in to post a comment.