DeepEval4Claude
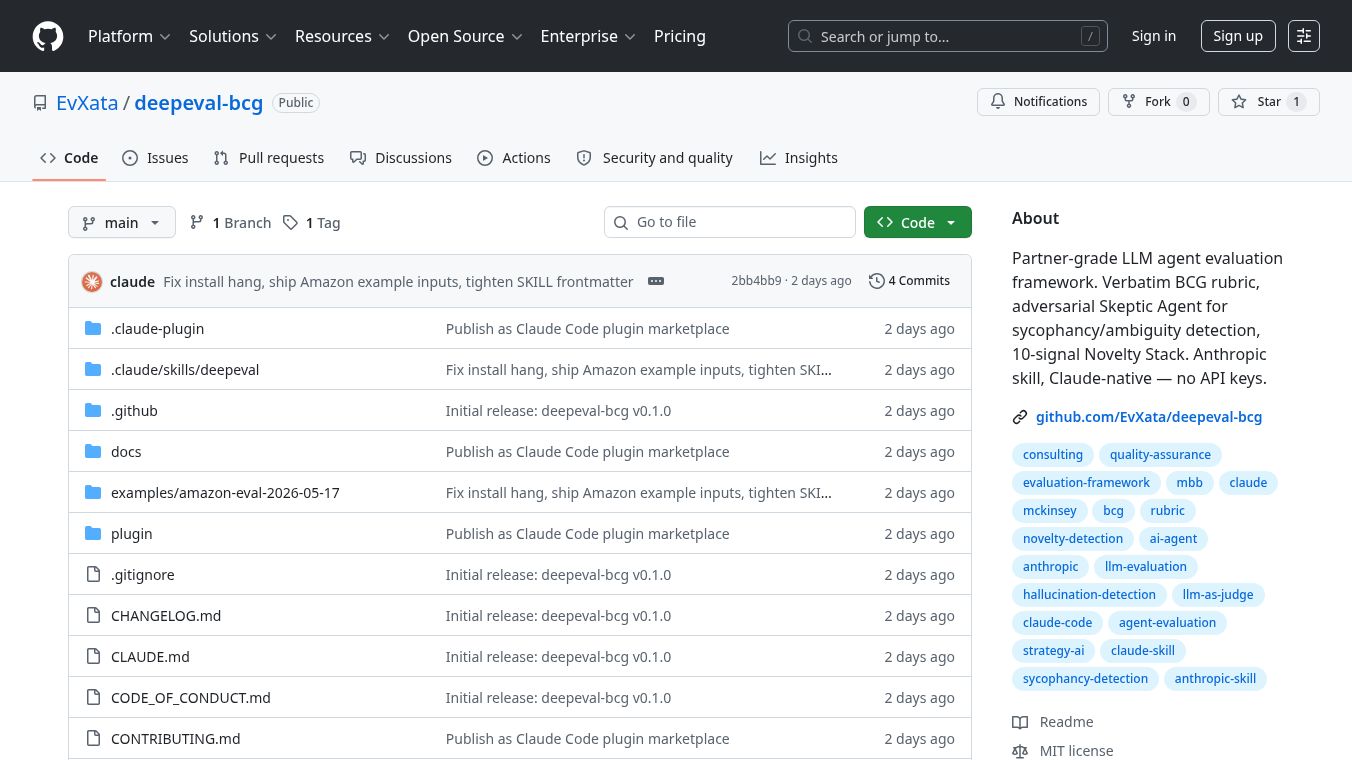
DeepEval4Claude is a specialized tool designed to evaluate the quality of AI responses using a strict set of rules from Boston Consulting Group. It helps developers and businesses ensure that their AI agents make clear decisions and do not simply agree with users without thinking. This tool is built to catch common mistakes that other evaluation systems often miss.
Benefits
DeepEval4Claude offers several key advantages for anyone working with AI agents. It uses a specific eight-point scoring system that mimics how top management consultants grade their analysts. This ensures that AI outputs are not just generic but are actually useful for senior leadership. The tool specifically targets two major problems in AI behavior. First, it stops the AI from making choices silently when the question is unclear. Second, it prevents the AI from agreeing with wrong ideas just to please the user. The framework includes a built-in skeptic agent that challenges the AI to prove its points. It also uses a special set of signals to find real insights instead of standard business advice. The entire process runs inside the Claude Code environment without needing any special API keys or passwords.
Use Cases
This tool is best used by companies that rely on AI to solve complex business problems. It works well for teams building customer service bots that need to handle tricky questions. It is also useful for analysts who want to verify that their AI-generated reports meet high professional standards. Users can run the tool on any document or text file to check its quality. The system can automatically generate a report showing whether the content passed or failed specific checks. It can also be used to collect feedback from the AI itself to improve future results. Teams can set up a schedule to run these checks every day or week to maintain high quality standards.
Pricing
The tool is available as a free plugin within the Claude Code marketplace. There are no hidden fees or subscription costs mentioned for using the basic evaluation features. Users can install it directly through the application interface or by running a simple command in their terminal. The free tier includes all the core evaluation capabilities needed for daily use.
Vibes
Users who have tried this tool report that it provides a much clearer view of AI performance than standard tests. Many developers appreciate how it catches subtle errors that other tools overlook. The feedback loop created by the tool helps teams learn quickly from mistakes. Some users note that the strict rules make the AI feel more professional and reliable. The community around this project seems active and focused on improving the accuracy of AI evaluations. Overall, the reception is positive among those looking for rigorous testing methods.
Additional Information
The project is open source and follows the MIT License. This means anyone can use, modify, and share the code freely. The developers have published their work on GitHub for others to review and contribute to. The methodology behind the tool is based on real-world frameworks used by major consulting firms. It also references several academic studies on how to evaluate large language models. The team welcomes contributions from people who want to add support for other languages or new types of business rules. The project aims to become a standard tool for testing AI agents in professional settings.
This content is either user submitted or generated using AI technology (including, but not limited to, Google Gemini API, Llama, Grok, and Mistral), based on automated research and analysis of public data sources from search engines like DuckDuckGo, Google Search, and SearXNG, and directly from the tool's own website and with minimal to no human editing/review. THEJO AI is not affiliated with or endorsed by the AI tools or services mentioned. This is provided for informational and reference purposes only, is not an endorsement or official advice, and may contain inaccuracies or biases. Please verify details with original sources.


Comments
Please log in to post a comment.