Cached Claude API
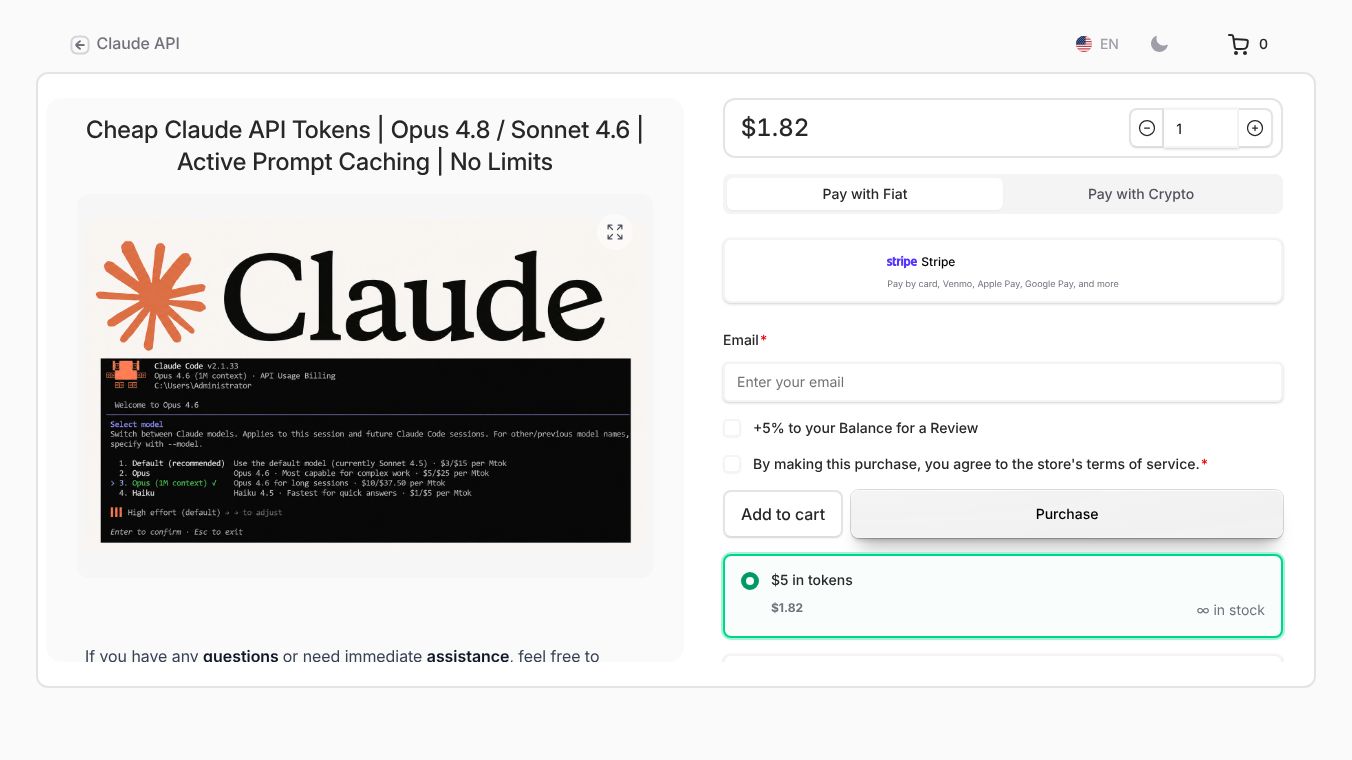
The Complete Guide to Claude API Prompt Caching
What is Cached Claude API
The Cached Claude API is a feature built into the Anthropic platform that helps developers save money when using their AI models. It works by storing parts of your request that do not change between calls. When you send a request with the same unchanged parts, the system uses the stored version instead of processing it again. This results in a much lower cost for those parts of the request.
This feature is especially useful for applications that send large amounts of text, such as system instructions, tool definitions, or long documents, with every single request. Without this feature, you would pay full price for those tokens hundreds or thousands of times. With caching, you only pay a small fee to store the data once and then a tiny fee to read it later.
Benefits
The main benefit of using prompt caching is significant cost reduction. When a cached part of your request is used, you pay only 10% of the normal input price. This means you save 90% on the cost of those specific tokens.
For example, if you have a system prompt that is 30,000 tokens long, it normally costs $0.09 per request. With a cache hit, that same prompt costs only $0.009. For applications with high traffic, this can lead to savings of thousands of dollars every month.
Another benefit is improved efficiency. The system handles the repeated work internally, allowing your application to run faster and more smoothly. Developers can focus on building features rather than worrying about token costs for static content.
Use Cases
Prompt caching is ideal for any application that sends large, stable context with every request. Common use cases include:
- System Prompts:Applications that use long instructions to define how the AI should behave. These instructions rarely change during a session.
- Tool Definitions:When an application uses many tools, the descriptions of those tools can be cached. This is common in complex workflows.
- Long Documents:If a user uploads a long contract or report and asks multiple questions about it, the document text can be cached. Only the new questions need to be processed.
- RAG Systems:Retrieval-Augmented Generation systems often fetch the same chunks of data repeatedly. Caching these chunks saves money.
- Multi-Turn Agents:In conversations where the AI remembers past steps, the history of the conversation can be cached as it grows.
Developers can choose between two cache tiers. The default tier lasts for five minutes and has a small extra cost to write data. The extended tier lasts for one hour but costs twice as much to write. The five-minute tier is best for active conversations, while the one-hour tier is better for batch jobs with long gaps between requests.
Pricing
The pricing for cached requests is based on the model you use. For Sonnet 4.6, the standard input price is $3.00 per million tokens. When you use the cache, the read price drops to $0.30 per million tokens. This is a 90% discount.
There is a small surcharge to write data to the cache. For the five-minute tier, the write cost is $3.75 per million tokens. For the one-hour tier, the write cost is $6.00 per million tokens. Despite the higher write cost, the savings from reading the data repeatedly far outweigh the initial write fee.
Vibes
Developers who use prompt caching report that it is a game changer for their budgets. Many teams that were struggling with high token costs found that enabling caching immediately reduced their bills by over 90% for the cached portions.
Users appreciate the simplicity of the feature. Once they understand where to place the cache control markers in their code, the savings happen automatically. The ability to layer multiple caches, such as a global prefix and a tenant-specific prefix, adds flexibility for complex applications.
Some users note that they must be careful to avoid dynamic data like timestamps in the cached sections. If they do not, the cache will miss every time. However, once they fix this, the system works reliably and provides consistent savings.
Additional Information
Prompt caching is available on the latest models from Anthropic, including Sonnet 4.x, Opus 4.x, and Haiku 4.x. Older models are being phased out and do not support this feature fully.
The feature is designed to be easy to implement using the official Anthropic SDKs for languages like Python and TypeScript. Developers can start with the default five-minute cache and switch to the one-hour tier if their traffic patterns require it. The system provides clear metrics in the API response so developers can track how often the cache is being used and adjust their strategy accordingly.
This content is either user submitted or generated using AI technology (including, but not limited to, Google Gemini API, Llama, Grok, and Mistral), based on automated research and analysis of public data sources from search engines like DuckDuckGo, Google Search, and SearXNG, and directly from the tool's own website and with minimal to no human editing/review. THEJO AI is not affiliated with or endorsed by the AI tools or services mentioned. This is provided for informational and reference purposes only, is not an endorsement or official advice, and may contain inaccuracies or biases. Please verify details with original sources.
Comments
Please log in to post a comment.